Linked list
adalah struktur data yang terdiri dari serangkaian rekaman data yang memiliki
penunjuk untuk mengarahkan ke rekaman data yang ada setelah rekaman data ini.

Untuk menggunakan linked list, kita
memerlukan memory allocation untuk menyiapkan sebagian memori yang akan
digunakan oleh linked list.
Contoh:
int *cth = (int *) malloc(sizeof(int));
char *ct = (char *)
malloc(sizeof(char));
*cth = 205;
*ct = ‘A’;
printf( “%d
%c\n”, *cth, *ct );
Untuk melepas memori yang tidak digunakan
lagi, dapat digunakan fungsi free.
Contoh:
free(cth);
free(ct);
Pada materi kali ini, kita membahas tentang Linked List dalam bahasa pemrograman C. Untuk kali ini kita akan fokus terhadap beberapa jenis Linked List yang lebih dalam termasuk :
1. Circular Singly Linked List
2. Doubly Linked List
3. Circular Doubly Linked List
Linked List sendiri adalah struktur data yang menyimpan sebuah data serta sebuah referensi untuk menunjukkan data selanjutnya dalam urutan tertentu.
Circular Single Linked List
Dalam Circular Single Linked List, untuk mengakses bagian mana pun, kita perlu melewati data pertama yang ada dalam urutan. Jika dalam pengecekan kita berada dalam tengah urutan, maka tidak mungkin kita dapat mengakses data yang berada sebelum bagian di mana kita berada. Nilai NULL dalam Circular Single Linked List tidak disimpan dalam urutan data.
Berikut ini gambar untuk memasukkan nilai awal dalam Circular Single Linked List, Sama halnya seperti insertion dalam Single Linked List.

*data = node
Doubly Linked List
Tidak seperti Single Linked List, Doubly Linked List dapat menunjuk ke data setelah urutan saat ini dan data sebelumnya. Karena Doubly Linked List dapat melakukan hal tersebut, tentu saja membuat Doubly Linked List lebih kompleks. Bagian dari Doubly Linked List dibagi menjadi tiga, yaitu data dari urutan data itu sendiri, pointer untuk menuju ke data selanjutnya, dan pointer untuk menuju data sebelumnya.
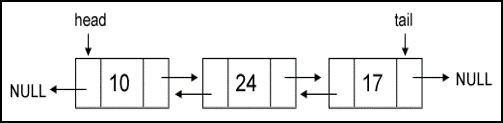
Untuk insertion dalam Doubly Linked List dapat terjadi pada awal urutan data, akhir urutan data, maupun dalam tengah – tengah urutan data. Berikut penjelasan lebih lengkapnya.
Insertion pada Awal Urutan Data
Untuk melakukan Insertion dalam Doubly Linked List kita harus memberi ruangan dalam memori untuk data baru yang ingin dimasukkan. Setelah itu, kita harus mengecek terlebih dahulu apakah urutan data yang ada kosong atau tidak. Jika urutan data tersebut kosong, maka pointer untuk urutan setelah data ini dan sebelum data ini akan menjadi NULL. Jika urutan data tersebut tidak kosong, maka data yang sebelumnya menjadi awal dari urutan tersebut menjadi urutan kedua, dan data baru ini menjadi data pertama.

Insertion pada Akhir Urutan Data
Kurang lebih sama seperti Insertion pada Awal Urutan Data, Insertion pada Akhir Urutan Data hanya berbeda pada bagian jika urutan data tidak kosong. Tepatnya jika urutan data tidak kosong, maka kita harus mencari akhir dari urutan data ini. Selama data setelah urutan saat ini tidak sama dengan NULL, maka kita akan terus berpindah urutan. Saat telah mencapai akhir, maka data yang paling akhir akan menjadi data sebelum data terakhir, dan data baru akan menjadi data terakhir.

Insertion pada Tengah - Tengah Data
Bagian ini cukup berbeda dengan kedua Insertion diatas, karena lokasi yang ingin dimasukkan sebuah data sudah di tentukan oleh pengguna. Konsep awal sebenarnya sama dengan dua Insertion diatas, namun bagian yang berbeda adalah kita harus mencari lokasi yang dimaksud terlebih dahulu sebelum memasukkan data.

Setelah Insertion, terdapat juga Delete. Delete dalam Doubly Linked List dibagi menjadi empat, yaitu Delete the only data, delete the head, delete the tail, dan terakhir Delete on a specified location.
Delete the Only Data
Dapat menggunakan metode free dalam bahasa C, serta menghapus hubungan yang ada dalam data.

Delete the Head
Sebelum menggunakan metode free, kita perlu mengatur agar urutan awal dari data tidak hilang. Setelah menggunakan metode free, kita harus memastikan bahwa hubungan antara data awal yang baru dengan data kedua yang baru tidak hilang.

Delete the Tail
Kita akan membuat data sebelum data terakhir menjadi yang terakhir dan melakukan metode free untuk data terakhir yang ingin dibuang. Setelah data terakhir dibuang, kita juga perlu memastikan bahwa hubungan antara data awal dengan data akhir yang baru tidak terputus.

Delete on a Specified Location
Sebelum menghapus data, kita perlu mencari data yang ingin dihapus, serta memastikan seluruh hubungan antar data tidak terputus setelah data spesifik yang telah ditunjuk dihapus.

Circular Doubly Linked List
Sebenarnya tidak jauh berbeda dengan Circular Single Linked List, Circular Doubly Linked List hanya memiliki satu perbedaan, yaitu seluruh data dalam Circular Doubly Linked List memiliki 2 pointer.

Materi hari ini membahas tentang proses yang dapat terjadi dalam Linked List. Dua proses pengumpulan data yang dibahas hari ini adalah Stack & Queue. Bagiamanakah proses ini terjadi, serta bagaimana cara implementasi dalam Bahasa C? Kita akan membahas hal tersebut dibawah ini.
Yang ditekankan saat ini adalah operasi dalam Linked List. Beberapa operasi yang ada adalah push(), pop(), serta top(). top() juga dikenal sebagai peek().
Ilustrasi dari push(), pop(), serta top() dalam array (Stack)

Ilustrasi dari push(), pop(), serta top() dalam array(Queue)

Contoh fungsi dari push() dalam Bahasa C

Contoh fungsi dari pop() dalam Bahasa C

Contoh fungsi dari top() dalam Bahasa C

Kesimpulannya,
push() adalah fungsi untuk menambahkan sebuah data ke dalam kumpulan data.
pop() adalah fungsi untuk menghapus sebuah data dalam kumpulan data yang ada.
top() atau peek() adalah fungsi untuk mengakses data paling pertama yang ada tanpa mengubah kumpulan data yang ada.
Perbedaan dari Stack dengan Queue adalah urutan dari kumpulan datanya. Dalam Stack, data yang dimasukkan terlebih dahulu akan dapat dikeluarkan setelah data lain telah keluar dahulu. Biasa disebut dengan istilah LIFO (Last In First Out). Sedangkan dalam Queue, data yang dimasukkan terlebih dahulu akan keluar juga terlebih dahulu. Biasa disebut dengan istilah FIFO (First In First Out).











Sumber:
Hash Table
Hashing adalah teknik untuk memberi identifikasi pada objek tertentu dari sekelompok objek yang mirip dengan objek tersebut. Dengan begitu, kita dapat mengakses objek tersebut dengan cepat.
Ambil contoh jika kita memiliki sebuah objek dan kita ingin memberi sebuah key kepada objek tersebut. Untuk menyimpan nilai dari key tersebut, kita dapat menggunakan array simpel dimana index dari array tersebut dapat menjadi key (integer) dari objek yang ingin dicari. Namun, ada beberapa kasus dimana nilai dari key sendiri cukup besar dan tidak dapat digunakan langsung dari index array, dan kita harus menggunakan hashing.
Hash Table adalah tabel (array) untuk menyimpan string awal. Ukuran dari hash table biasanya beberapa kali lebih rendah dari total angka dari string, maka beberapa string dapat mempunyai hashed-key yang sama.

Berikut contoh source code dari menyatakan data dengan hash key serta cara menentukan value dari key – nya.

Hash string dapat dijadikan key dengan beberapa cara yang disebut sebagai hash function. Cara – cara tersebut termasuk :
A. Mid-square
B. Division
C. Folding
D. Digit Extraction
E. Rotating Hash
A. Mid-square
Cara mid-square dapat digunakan dengan cara mencari sebuah value dari string dengan cara apapun, lalu dari value tersebut kita akan memangkatkan dua dari value tersebut. Dari hasil pangkat dua tersebut, diambil angka atau serangkaian angka dari tengah” value tersebut untuk menjadi key - nya.
Contoh :
Value dari string: 717
Hasil pangkat 2 dari value: 514.089
Key yang ditentukan: 40
B. Division (Paling sering digunakan)
Sama pada bagian awal mid-square, kita perlu menentukan value sebagai pengidentfikasi string yang ada. Dari value tersebut kita akan membagi value tersebut dengan operator modulus. Di - modulus dengan siapa? Biasanya dengan angka prima, dari besar tabel yang ada atau ukuran memori yang digunakan.
Contoh:
Ukuran Tabel: 97
String: “COBB”
Penghitungan value string: (64*4 + 3 + 15 + 2 + 2) % 97 = 88
*64 adalah ASCII dari ‘A’, serta string terdiri dari huruf kapital saja
C. Folding
Folding adalah cara menentukan hash key dengan membagi string yang ada menjadi beberapa bagian terlebih dahulu. Setelah terbagi, kita dapat menemukan hash key dengan menambahkan value yang terdapat dalam string.
Contoh:
Key: 321
Pembagian: 32 dan 1
Total: 33 -> menjadi value hash key
D. Digit Extraction
Serangkaian angka yang telah ditentukan akan dianggap menjadi hash address dalam cara digit extraction. Dari angka tersebut, kita akan memilih beberapa angka dari serangkaian angka tadi untuk dijadikan hash key.
Contoh:
Hash address: 27.589
Ambil digit pertama, ketiga dan kelima, lalu kita akan mendapatkan hash key dengan nilai 259.
E. Rotating Hash
Rotating hash adalah cara yang tidak dapat digunakan tanpa melakukan cara lain terlebih dahulu. Mengapa? Karena rotating hash diambil dari hash address yang dihasilkan oleh cara lain seperti division atau mid-square. Setelah mendapatkan hash address dengan cara rotating hash kita akan mendapatkan key baru dengan cara memutar hash address yang ada.
Contoh:
Hash address: 20021
Hasil: 12002
Dari cara” tersebut, kita dapat menemukan value key yang sama dari data yang berbeda. Masalah ini biasa dikenal dengan nama Collision. Bagaimanakah kita dapat mengatasi masalah ini? Terdapat dua cara yaitu Linear Probing dan Chaining.
A. Linear Probing
Cara ini dapat dilakukan dengan mencari tempat kosong selanjutnya dan menempatkan data yang ada di tempat tersebut. Maksud dari tempat yakni key baru yang belum ditempati data.
Contoh :

Linear probing memiliki kekurangan jika bertemu dengan banyak collision. Karena dengan Linear Probing kita perlu mencari tempat yang kosong untuk data baru. Jika terjadi banyak collision maka proses mencari tempat kosong untuk data baru akan memakan waktu yang cukup lama.
B. Chaining
Chaining dapat dilakukan dengan cara menghubungkan 2 data yang memiliki key atau index yang sama. Bagaimana cara menghubungkan 2 data yang berbeda dengan key yang sama? Dengan cara Linked List yang telah kita bahas sebelumnya.

Binary Tree
Sebelum masuk ke dalam binary tree, kita perlu membahas tree terlebih dahulu. Tree adalah struktur data yang non-linear yang merepresentasikan hubungan antara objek dalam data.

Tree terdiri dari satu atau lebih nodes. Dari gambar diatas, kita mendapatkan derajat dari tree tersebut adalah 3 karena hubungan terbanyak yang dimiliki dalam tree tersebut adalah 3.
Derajat dari C adalah 2, dan tinggi tree tersebut adalah 3.
Yang berada diatas cabang disebut sebagai parent, contohnya adalah parent dari C adalah A. Sebaliknya, yang berada pada bawah cabang disebut dengan children. Contohnya adalah children dari B adalah E.
Sibling adalah sebutan untuk dua atau lebih data berbeda yang berada di level yang sama dengan parent yang sama. Contohnya adalah F dengan G.
Ancestor adalah parent dari parent suatu data. Contohnya adalah ancestor dari F adalah A.
Yang berada di level 0, atau data yang menempati tempat teratas dalam sebuah tree, disebut sebagai root.
Binary tree adalah tree yang tiap node yang ada dalam tree tersebut memiliki paling banyak 2 children. Node yang tidak memiliki child disebut sebagai leaf.

Contoh Binary Tree
Binary tree terbagi menjadi 4 tipe. Perfect binary tree, complete binary tree, skewed binary tree dan balanced binary tree adalah tipe-tipe dari binary tree.
A. Perfect Binary Tree
Adalah binary tree yang semua node - nya antara kosong atau memiliki tepat 2 anak.

B. Complete Binary Tree
Adalah binary tree yang seperti perfect binary tree di semua level kecuali level terakhir, dimana level terakhir akan selalu penuh dari kiri, sehingga tidak ada kekosongan di tengah level namun dapat memilki leaf di bagian kanan maupun node yang hanya memiliki 1 children. Perfect binary tree juga merupakan salah satu complete binary tree.

C. Skewed Binary Tree
Adalah binary tree yang node – nya hanya memiliki 1 child.

D. Balanced Binary Tree
Adalah binary tree yang seimbang dalam suatu aspek. Contohnya adalah height balanced binary tree. Dapat dikatakan height balanced binary tree jika binary tree tersebut seimbang dari kanan dan kiri. Atau, perbedaan tinggi dari kanan dan kiri tidak lebih dari 1.



Sumber:
BINUS University – Data Structures – Linked List
II (L)
BINUS University – Data Structures – Stack & Queue (L)
Comments
Post a Comment